在coding过程中会时不时地遇到字符集的编码问题,之前就一直没弄清楚过,很是头疼,因此查阅了一些资料,并对各种字符集(Ascii、Unicode、GB2312)、编码(UTF8、GBK)以及不同编码之间的转换做一个总结。
字符集(Charcater Set)与字符编码(Encoding)
字符集(Charcater Set 或 Charset):是一个系统支持的所有抽象字符的集合,也就是一系列字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。常见的字符集有: ASCII 字符集、Unicode 字符集等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个字符集(如字母表或音节表),与计算机能识别的二进制数字进行配对。即它能在符号集合与数字系统之间建立对应关系,是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息,而计算机的信息处理系统则是以二进制的数字来存储和处理信息的。字符编码就是将符号转换为计算机能识别的二进制编码。
一般一个字符集等同于一个编码方式,ANSI 体系( ANSI 是一种字符代码,为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符)的字符集如 ASCII、ISO 8859-1、GB2312、 GBK 等等都是如此。一般我们说一种编码都是针对某一特定的字符集。一个字符集上也可以有多种编码方式,例如 UCS 字符集(也是 Unicode 使用的字符集)上有 UTF-8、UTF-16、UTF-32 等编码方式。
从计算机字符编码的发展历史角度来看,大概经历了三个阶段:
- 第一个阶段:ASCII 字符集和 ASCII 编码。 计算机刚开始只支持英语(即拉丁字符),其它语言不能够在计算机上存储和显示。ASCII 用一个字节( Byte )的 7 位(bit)表示一个字符,第一位置 0。后来为了表示更多的欧洲常用字符又对 ASCII 进行了扩展,又有了 EASCII,EASCII 用 8 位表示一个字符,使它能多表示 128 个字符,支持了部分西欧字符。
- 第二个阶段:ANSI 编码(本地化) 为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符。比如:汉字 ‘中’ 在中文操作系统中,使用 [0xD6,0xD0] 这两个字节存储。 不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码。 不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。
- 第三个阶段:UNICODE(国际化) 为了使国际间信息交流更加方便,国际组织制定了 UNICODE 字符集,为各种语言中的每一个字符设定了统一并且唯一的数字编号,以满足跨语言、跨平台进行文本转换、处理的要求。UNICODE 常见的有三种编码方式:UTF-8、UTF-16、UTF-32。
下面是用一个树状图表示的由ASCII发展而来的各个字符集和编码的分支:
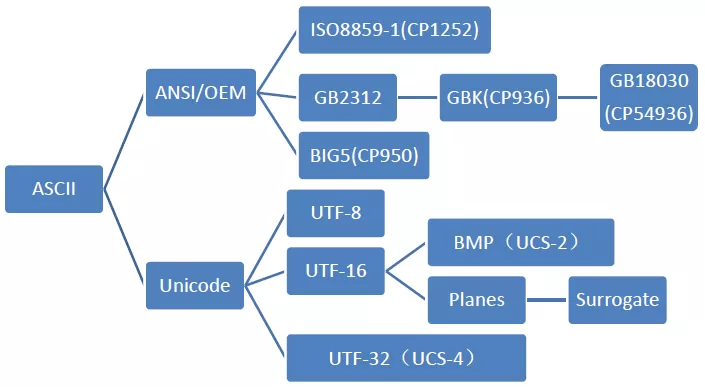
ASCII、Unicode字符集
ASCII码
在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。ASCII码一共规定了128个字符的编码,比如空格”SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
非ASCII编码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用ASCII码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。但是不同的国家有不同的字母,因此会出现同一中编码对应不同字符的情况。至于亚洲国家的文字,使用的符号更多,因此用一个字节来编码字符显然是不够的,必须使用多个字节表达一个字符或符号,比如中文中常见的编码方式是GB2312,使用两个字节表示一个汉字。
GBK编码
GBK是国家标准GB2312基础上扩容后兼容GB2312的标准。GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示,为了区分中文,将其最高位都设定成1。GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBD大。GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换。
Unicode字符集
世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。Unicode应运而生,给每个符号给予一个独一无二的编码,现在的规模可以容纳100多万个符号。Unicode的编码空间可以划分为17个平面(plane),每个平面包含2的16次方(65536)个码位。17个平面的码位可表示为从U+0000到U+10FFFF,共计1114112个码位,第一个平面称为基本多语言平面(Basic Multilingual Plane, BMP),或称第零平面(Plane 0)。其他平面称为辅助平面(Supplementary Planes)。基本多语言平面内,从U+D800到U+DFFF之间的码位区段是永久保留不映射到Unicode字符,所以有效码位为1112064个。
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。此外,还有两个比较严重的问题,第一个如何才能区分Unicode和ASCII?计算机如何知道三个字节表示一个符号而不是表示三个符号;第二个问题就是如果Unicode统一规定,每个符号要3个或4个字节表示,对于只需用一个字节就可以编码的英文字母,势必会浪费存储,而且文本文件也会增大不少。这两个问题导致的结果就是出现了Unicode的多种存储方式,也就是说有多种不同的二进制格式,可以用来表示Unicode。
UTF-8、UTF-16编码以及不同编码之间的转换
UTF-8编码
UTF-8是使用较为广泛的一种Unicode实现方式,其他实现方式还包括UTF-16、UTF-32。UTF-8的最大特点就是它是一种变长的编码方式,使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,UTF-8的编码规则很简单,主要有下面两点:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的Unicode码,对于英文字母,UTF-8编码和ASCII码是相同的。
- 对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10,剩下的二进制位就是这个符号的Unicode码。
根据这个编码规则很容易实现Unicode和UTF-8编码之间的转换,两种编码的对应关系如下表所示:
| Unicode编码 | UTF-8编码(二进制) |
|---|---|
| U+0000 – U+007F | 0xxxxxxx |
| U+0080 – U+07FF | 110xxxxx 10xxxxxx |
| U+0800 – U+FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| U+10000 – U+10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
其中绝大部分的中文用三个字节编码,部分中文用四个字节编码。UTF-8编码的主要优点有:1.兼容ASCII码;2.没有字节序(大小端)的问题,适合网络传输;3.存储英文和拉丁文等比较节省存储空间。但也存在不足,例如边长编码不利于文本处理,对于CJK文字比较浪费存储空间。
UTF-16编码
UTF-16也是一种变长编码,对于一个Unicode字符被编码成1至2个码元,每个码元为16位。在基本多语言平面(码位范围U+0000-U+FFFF)内的码位UTF-16编码使用1个码元且其值与Unicode是相等的(不需要转换),
在辅助平面(码位范围U+10000-U+10FFFF)内的码位在UTF-16中被编码为一对16bit的码元(即32bit,4字节),称作代理对(surrogate pair)。组成代理对的两个码元前一个称为前导代理(lead surrogates)范围为0xD800-0xDBFF,后一个称为后尾代理(trail surrogates)范围为0xDC00-0xDFFF。
Unicode、UTF-8编码的互转
void UTF8ToUnicode(wchar_t* pOut,char *pText)
{
char* uchar = (char *)pOut;
uchar[1] = ((pText[0] & 0x0F) << 4) + ((pText[1] >> 2) & 0x0F);
uchar[0] = ((pText[1] & 0x03) << 6) + (pText[2] & 0x3F);
return;
}
void UnicodeToUTF8(char* pOut,wchar_t* pText)
{
//注意 WCHAR高低字的顺序,低字节在前,高字节在后
char* pchar = (char *)pText;
pOut[0] = (0xE0 | ((pchar[1] & 0xF0) >> 4));
pOut[1] = (0x80 | ((pchar[1] & 0x0F) << 2)) + ((pchar[0] & 0xC0) >> 6);
pOut[2] = (0x80 | (pchar[0] & 0x3F));
return;
}Unicode、GB2312编码的互转
//注:此处用到windows编码转换的函数
void UnicodeToGB2312(char* pOut,wchar_t uData)
{
WideCharToMultiByte(CP_ACP,NULL,&uData,1,pOut,sizeof(wchar_t),NULL,NULL);
return;
}
void GB2312ToUnicode(wchar_t* pOut,char *gbBuffer)
{
MultiByteToWideChar(CP_ACP,MB_PRECOMPOSED,gbBuffer,2,pOut,1);
return ;
}UTF-8、GBK(GB2312)编码的互转
void GB2312ToUTF8(string& pOut,char *pText, int pLen)
{
char buf[4];
int nLength = pLen* 3;
char* rst = new char[nLength];
memset(buf,0,4);
memset(rst,0,nLength);
int i = 0;
int j = 0;
while(i < pLen)
{
if( *(pText + i) >= 0)
{
rst[j++] = pText[i++];
}
else
{
wchar_t pbuffer;
Gb2312ToUnicode(&pbuffer,pText+i);
UnicodeToUTF_8(buf,&pbuffer);
unsigned short int tmp = 0;
tmp = rst[j] = buf[0];
tmp = rst[j+1] = buf[1];
tmp = rst[j+2] = buf[2];
j += 3;
i += 2;
}
}
rst[j] = ' ';
pOut = rst;
delete []rst;
return;
}
void UTF8ToGB2312(string &pOut, char *pText, int pLen)
{
char * newBuf = new char[pLen];
char Ctemp[4];
memset(Ctemp,0,4);
int i =0;
int j = 0;
while(i < pLen)
{
if(pText > 0)
{
newBuf[j++] = pText[i++];
}
else
{
WCHAR Wtemp;
UTF_8ToUnicode(&Wtemp,pText + i);
UnicodeToGB2312(Ctemp,Wtemp);
newBuf[j] = Ctemp[0];
newBuf[j + 1] = Ctemp[1];
i += 3;
j += 2;
}
}
newBuf[j] = ' ';
pOut = newBuf;
delete []newBuf;
return;
}另外一种实现GBK和UTF-8编码转换的方法:
string GBKToUTF8(const char* strGBK)
{
int len = MultiByteToWideChar(CP_ACP, 0, strGBK, -1, NULL, 0);
wchar_t* wstr = new wchar_t[len + 1];
memset(wstr, 0, len + 1);
MultiByteToWideChar(CP_ACP, 0, strGBK, -1, wstr, len);
len = WideCharToMultiByte(CP_UTF8, 0, wstr, -1, NULL, 0, NULL, NULL);
char* str = new char[len + 1];
memset(str, 0, len + 1);
WideCharToMultiByte(CP_UTF8, 0, wstr, -1, str, len, NULL, NULL);
string strTemp = str;
if (wstr) delete[] wstr;
if (str) delete[] str;
return strTemp;
}
string UTF8ToGBK(const char* strUTF8)
{
int len = MultiByteToWideChar(CP_UTF8, 0, strUTF8, -1, NULL, 0);
wchar_t* wszGBK = new wchar_t[len + 1];
memset(wszGBK, 0, len * 2 + 2);
MultiByteToWideChar(CP_UTF8, 0, strUTF8, -1, wszGBK, len);
len = WideCharToMultiByte(CP_ACP, 0, wszGBK, -1, NULL, 0, NULL, NULL);
char* szGBK = new char[len + 1];
memset(szGBK, 0, len + 1);
WideCharToMultiByte(CP_ACP, 0, wszGBK, -1, szGBK, len, NULL, NULL);
string strTemp(szGBK);
if (wszGBK) delete[] wszGBK;
if (szGBK) delete[] szGBK;
return strTemp;
}




