前言
不知道大家有没有注意到,有些APP注册的时候,会提示用户名已经被占用,需要更换一个。
实现这个功能的方式有很多种,现在我们来逐一看一下不同设计方案的优缺点。
数据库方案
这种方式实现起来最简单,但是在数据量大的情况下,比如十亿用户数据时会带来以下问题:
- 存在延迟比较大的性能问题,如果数据量很大,查询速度会变慢,而且数据库查询涉及到应用服务器和数据库服务器之间的网络通信,建立连接、发送查询、接收响应所需的时间也会导致延迟。
- 数据库负载过大。频繁执行 SELECT 查询来检查用户名的唯一性,每个查询都会消耗数据库资源,包括 CPU 和 I/O 资源。
- 可扩展性差。数据库对并发连接和资源有限制。如果注册率持续上升,数据库服务器可能难以处理不断增加的传入请求。数据库的垂直扩展(向单个服务器添加更多资源)可能成本高昂,并且可能存在局限性。

缓存解决方案
为了解决检查用户名唯一性的数据库调用的性能问题,我们可以引入高效的 Redis 缓存方案。

import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.redisson.api.RMap;
public class UserExistenceChecker {
// Redis hash map name to store user information
private static final String USER_HASH_NAME = "users";
public static void main(String[] args) {
// Create a Redisson client
RedissonClient redisson = createRedissonClient();
// Retrieve the hash map to store user information
RMap<String, String> users = redisson.getMap(USER_HASH_NAME);
// Add a user to the hash map
users.put("user123", "someUserInfo"); // Here "someUserInfo" could be a JSON string, UUID, etc.
// Check if a user exists
boolean exists = users.containsKey("user123");
System.out.println("User 'user123' exists? " + exists);
// Check for a non-existent user
exists = users.containsKey("user456");
System.out.println("User 'user456' exists? " + exists);
// Shutdown the Redisson client
redisson.shutdown();
}
// Helper method to create a Redisson client
private static RedissonClient createRedissonClient() {
Config config = new Config();
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379") // Adjust to your Redis address
.setPassword("yourpassword"); // Provide your Redis password if any
return Redisson.create(config);
}
}这个方案最大的问题是内存占用过大,假设每个用户名大约需要15字节的内存,如果要存储10亿个用户名,就需要15GB的内存。
总内存 = 每条记录的内存使用量 * 记录数 = 15 字节/记录 * 1,000,000,000 条记录 = 15,000,000,000 字节 ≈ 15,000,000 KB ≈ 15,000 MB ≈ 15 GB
布隆过滤器方案
如果直接通过缓存进行判断,会占用过多的内存,有没有更好的办法?Bloom Filter 是一个很不错的选择。
什么是布隆过滤器?
Bloom Filter 是一种高度节省空间的随机数据结构,它用一个位数组来简洁地表示一个集合,并可以判断某个元素是否属于这个集合。
Bloom Filter 的这种高效是有代价的:在判断某个元素是否属于某个集合时,有可能错误地将不属于该集合的元素认为是属于该集合(false positive)。
因此,Bloom Filter 并不适合“零错误”的应用场景,但在可以容忍较低错误率的应用场景中,Bloom Filter 通过极少的错误实现了存储空间的大幅节省。
结构
从上面的分析可以知道,布隆过滤器的核心思想是利用一个位数组(bit array)和一组哈希函数。
位数组,每个位最初为 0:

在插入值x时,分别使用k个哈希函数(图中3个)对x的值进行哈希运算,并将哈希值与布隆过滤器的容量(位数组长度)取余数,并将结果所代表的相应位的值设置为1。
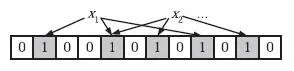
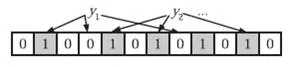
查找过程类似于插入过程,同样使用k个哈希函数对要查找的值进行哈希处理,只有哈希处理后得到的每个比特位的值为1时,才表示该值“可能”存在;反之,如果任意一个比特位的值为0,则表示该值一定不存在。例如y1一定不存在,而y2则可能存在。
Redis是支持Bloom filter这种数据结构的,我们来使用Redisson客户端简单实现一下代码:
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class UserExistenceChecker {
// Name of the Bloom Filter in Redis
private static final String BLOOM_FILTER_NAME = "user_existence_filter";
public static void main(String[] args) {
// Create a Redisson client
RedissonClient redisson = createRedissonClient();
// Retrieve or create a Bloom Filter instance
// Expected number of elements and false positive probability are parameters
RBloomFilter<String> bloomFilter = redisson.getBloomFilter(BLOOM_FILTER_NAME);
bloomFilter.tryInit(100000L, 0.001); // Initialize the Bloom Filter with expected elements and false positive rate
// Add a user to the Bloom Filter
bloomFilter.add("user123");
// Check if a user exists
boolean exists = bloomFilter.contains("user123"); // Should return true
System.out.println("User 'user123' exists? " + exists);
// Check for a non-existent user (might falsely report as true due to Bloom Filter's nature)
exists = bloomFilter.contains("user456"); // Assuming not added, should ideally return false, but could be a false positive
System.out.println("User 'user456' exists? " + exists);
// Shutdown the Redisson client
redisson.shutdown();
}
// Helper method to create a Redisson client
private static RedissonClient createRedissonClient() {
Config config = new Config();
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379"); // Adjust to your Redis address
// .setPassword("yourpassword"); // Provide your Redis password if any
return Redisson.create(config);
}
}优点:
- 节省内存空间:相比使用哈希表等数据结构,布隆过滤器通常需要更少的内存空间,因为它不存储实际的元素,而只存储元素的哈希值。如果存储10亿条记录,误差
probability为0.001,则只1.67 GB需要 的内存。相比原来的15G,已经大大减少了。 - 高效查找:布隆过滤器可以在常数时间内快速判断某个元素是否存在于集合中
(O(1)),而不需要遍历整个集合。
缺点:
- 存在误报率: Bloom filter 在判断某个元素是否存在的时候,存在一定的误报率。这意味着在某些情况下,它可能会误报某个元素存在,但不会误报某个元素不存在。不过这一般影响不大。
- 不能删除元素:布隆过滤器通常不支持从集合中删除元素,因为删除一个元素会影响其他元素的哈希值,增加误报率。
如何保证布隆过滤器方案没有误报?
这里可以考虑将Bloom filter与数据库相结合的方案。
使用Bloom Filter判断某个元素是否存在的时候,有一定概率会误报该元素存在,但是不会误报该元素不存在。
所以,当使用布隆过滤器判断某个元素不存在的时候,可以直接信任这个结果并返回。如果判断某个元素存在,此时不要完全信任它的判断,而是去数据库中查询真正的结果。
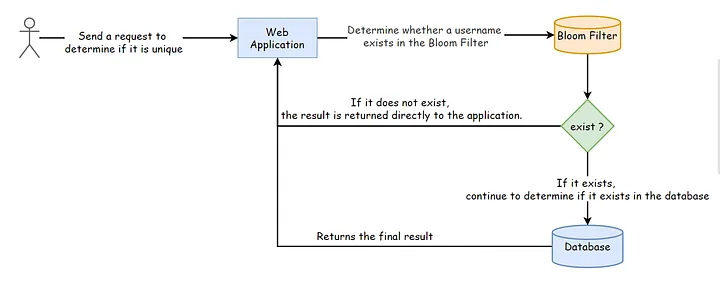
因为确定某个元素存在的概率已经很低了,所以实际访问数据库的量也会很小,整体压力不是很大。
可以从布隆过滤器中删除元素吗?
为什么 Bloom Filter 中的元素不能被删除呢?我们举一个例子来说明。
比如我们要从集合中删除成员“Jerry”,那么我们首先会用k(图中为2)个哈希函数来计算。由于“Jerry”已经是集合中的成员,所以位数组中对应位置肯定是1。如果要删除这个成员“Jerry”,我们需要将计算出的位置上的1全部设置为0。下图中,只需要将索引位置2和5的值都设置为0即可。
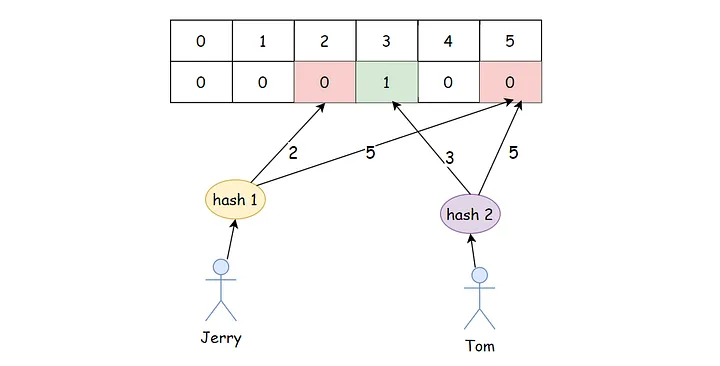
问题来了!现在我们假设“Tom”也已经是集合中的一个元素了。如果我们需要查询“Tom”是否在这个集合中,经过哈希函数计算后,我们会判断第三位和第五位是否为1。这时候我们得到的结果是第五位为0,也就是“Tom”不属于这个集合。很显然,这里是一个false positive。
所以,原始的Bloom Filter是不支持删除元素的,但是Counting Bloom Filter可以。
Counting Bloom Filter 的出现解决了上述问题,它将标准 Bloom Filter 的位数组的每一位扩展为一个小的计数器,当插入一个元素时,分别将对应的 k(k 为哈希函数个数)个计数器的值加 1,当删除一个元素时,分别将对应的 k 个计数器的值减 1。
由此我们可以看出,Counting Bloom Filter 在 Bloom Filter 的基础上增加了一个删除操作,但代价是占用多几倍的存储空间。基本原理是不是很简单呢?看下面这张图,就能明白它和 Bloom Filter 的区别在哪里了。
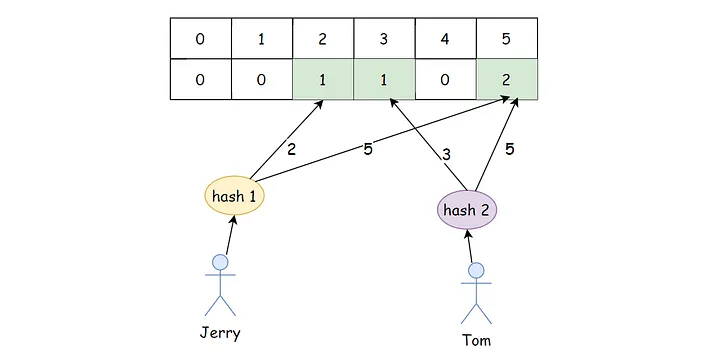
计数器大小的选择
计数布隆过滤器与布隆过滤器的一个主要区别是,计数布隆过滤器用计数器代替了布隆过滤器中的一位。
那么 Counter 应该设多大呢?这里就需要考虑空间利用率的问题了。从利用率的角度来说,当然是越大越好,因为 Counter 越大,可以表示的信息就越多。但是 Counter 越大,意味着占用的资源越多,往往会造成很大的空间浪费。
所以在选择Counter的时候,我们应该尽可能的满足要求。Counter的具体计算比较复杂,涉及到一系列的数学公式,这里就不展开了,有兴趣的朋友可以参考论文第6、7页:《Summary Cache: A Scalable Wide-Area Web Cache Sharing Protocol》,里面具体阐述了这一点。





